VirtualBox로 Hadoop Cluster 구축하기
개발 | 2017-06-01 14:39- Linux Mint 18.1 Cinnamon 64bit, Oracle Java 8, Hadoop 2.7.3 버전 기준으로 작성되었습니다.
- 저는 hadoop01(NameNode, DataNode), hadoop02(DataNode), hadoop03(DataNode), hadoop04(DataNode)라는 hostname으로 VM을 구축했습니다. 아래 내용을 참고해서 원하는대로 설정하셔도 됩니다. () 안의 내용은 각 VM의 역할입니다.
VirtualBox VM 생성
VirtualBox는 이미 설치된 것으로 가정하고 진행하겠습니다.
먼저 Linux Mint 설치 파일을 준비합니다. Linux Mint 18.1 Cinnamon 64bit 다운로드 에서 원하는 방식으로 다운로드 하시면 됩니다. 저는 Torrent를 사용해서 받았습니다.
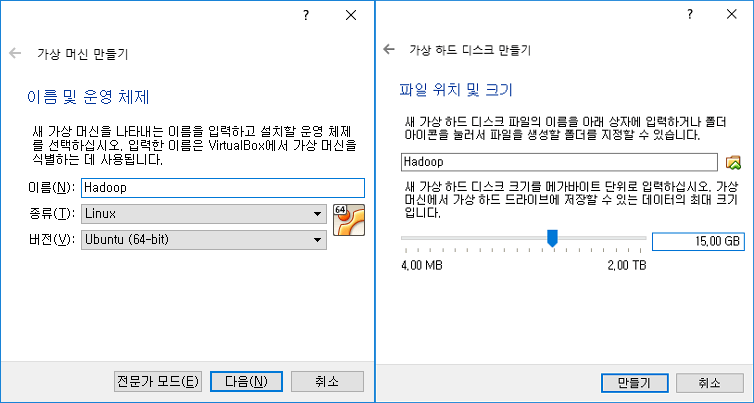
VirtualBox에서 새로운 VM을 생성합니다. Linux, Ubuntu (64bit) 를 선택하시면 됩니다. 생성 시에 특별히 설정할 건 없고, VDI 용량을 15GB 이상 으로 설정하는 걸 추천합니다.
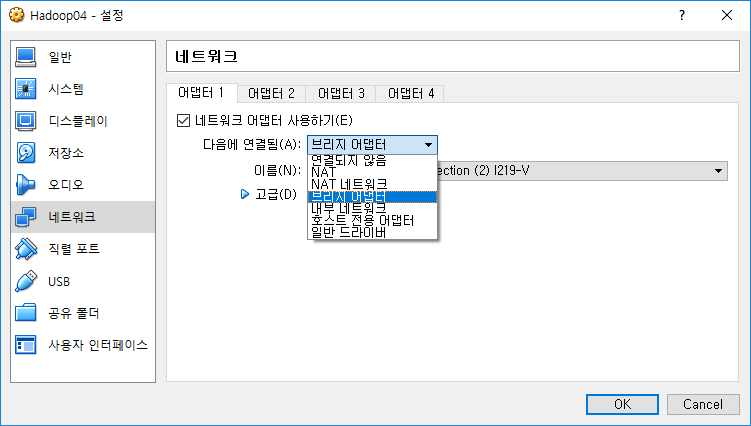
VM 생성 후에 네트워크 어댑터를 설정해줘야 합니다. 기본값은 NAT인데, 이를 브릿지 어댑터(호스트와 같은 네트워크에 물림)나 호스트 전용 어댑터(VM끼리 내부 네트워크 구성) 로 설정해줍니다. 저는 브릿지 어댑터로 설정하고 OS 내에서 IP를 수동으로 설정해줬습니다.
Linux Mint iso 파일로 부팅 후에 바탕화면의 Linux Mint Install을 실행해 OS를 설치해줍니다.
환경 구축
Hadoop이 OpenJDK로도 동작하지만, Oracle JDK에서 더 안정적으로 동작하는 듯 해서 Oracle JDK를 다음 명령어로 설치해줍니다. 뒤에서 사용할 SSH, VIM도 같이 설치하겠습니다. 설치 중에 터미널에 뜨는 안내에 따라서 설치를 진행해주세요.
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install ssh vim oracle-java8-set-default
그 후에 Hadoop을 설치합니다. 2017년 5월 31일 현재, 최신 버전은 2.8.0이지만, 여기선 2.7.3 버전을 사용하겠습니다. 버전이 다를 경우 설정 방법이 달라질 수 있습니다.
wget http://mirror.navercorp.com/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
tar xf hadoop-2.7.3.tar.gz
현재 경로에 hadoop-2.7.3가 만들어지고 압축이 해제됩니다. 폴더명을 바꾸고 싶으면 mv hadoop-2.7.3 바꿀이름 명령어를 사용합니다.
Hadoop 설정
Hadoop 폴더에 들어간 상태에서 vi etc/hadoop/hadoop-env.sh 로 설정 파일을 열어줍니다. JAVA_HOME 설정값을 JAVA_HOME=/usr/lib/jvm/java-8-oracle 로 수정해줍니다. bin/hadoop 명령어를 실행했을 때, hadoop 사용법이 출력되면 정상 설치된 것입니다.
이어서 vi etc/hadoop/core-site.xml 명령어로 아래와 같이 파일을 수정합니다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<!-- NameNode를 가리키도록 설정합니다 -->
</property>
</configuration>
vi etc/hadoop/hdfs-site.xml 명령어로 아래를 참고해 파일을 수정합니다.
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/(hadoop 폴더 절대 경로)/work/name</value>
<!-- NameNode에서 사용할 폴더 경로를 설정합니다 -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/(hadoop 폴더 절대 경로)/work/data</value>
<!-- DataNode에서 사용할 폴더 경로를 설정합니다 -->
</property>
</configuration>
수정 후에 mkdir work; mkdir work/data; mkdir work/name 명령어로 위 파일에서 지정한 경로에 폴더를 생성합니다.
vi etc/hadoop/yarn-site.xml 명령어로 아래와 같이 파일을 수정합니다.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
<!-- NameNode를 가리키도록 설정합니다 -->
</property>
</configuration>
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml; vi etc/hadoop/mapred-site.xml 명령어로 아래와 같이 파일을 수정합니다.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi etc/hadoop/slaves 명령어로 아래를 참고해 파일을 수정합니다.
hadoop01
hadoop02
hadoop03
hadoop04
DataNode를 실행할 VM의 hostname를 넣어주면 됩니다. 아래에서 /etc/hosts 파일을 수정해줄 것이기 때문에 위와 같이 설정했습니다.
아래 내용을 진행한 이후에는 설정 파일을 변경할 때마다 모든 VM 내의 설정 파일을 똑같이 수정 해줘야 합니다. scp 명령어를 사용하면 다른 VM으로 쉽게 파일을 복사할 수 있습니다. 설정 파일을 변경한 후에는 NameNode가 실행되는 VM에서 꼭 bin/hadoop namenode -format 명령어를 실행 해주세요.
VM 복제

기존 VM을 선택하고 우클릭해 복제를 선택합니다. 복제 시에 네트워크 주소 초기화 를 꼭 체크해주세요. 연결된 복제를 선택하면 용량을 절약할 수 있습니다.
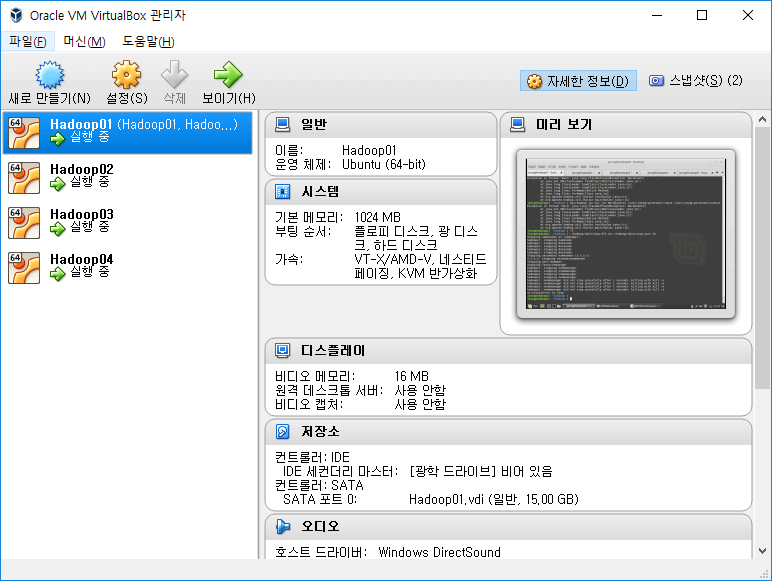
VM 복제가 완료되면 모두 실행해줍니다. Hadoop Cluster를 구동하기 위해선 모든 VM이 켜져있어야 합니다.
각 VM의 IP 확인 및 hosts 파일, hostname 수정
현재 모든 VM의 hostname이 동일한 상태이기 때문에 hostname을 서로 다르게 변경 해줘야 합니다. hostnamectl set-hostname 새로운hostname 명령어로 변경합니다.
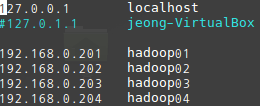
각 VM의 터미널에서 ifconfig 명령어를 실행해 IP를 확인합니다. 확인한 IP를 각 VM의 hosts 파일에 넣어줍니다. 명령어는 sudo vi /etc/hosts 입니다. 위에서 변경한 hostname에 맞춰서 작성 합니다.
SSH 키 생성 및 등록
현재 한 VM에서 다른 VM에 접속하려면 암호를 입력해야 하는 상태입니다. SSH 키를 등록해서 자동 로그인 되도록 해줘야 작업이 편리해집니다.
먼저 각 VM에서 ssh-keygen -t rsa 명령어로 키를 생성(전부 엔터)합니다. 생성한 이후에 ssh-copy-id 설정한hostname 명령어로 각 VM에서 본인을 포함한 모든 VM에 키를 등록 해줍니다.
구동 및 확인
위와 같이 모든 설정을 마친 후에 NameNode VM의 터미널에서 sbin/start-dfs.sh; sbin/start-yarn.sh 명령어로 Hadoop Cluster를 실행합니다. 다른 VM의 DataNode는 자동으로 실행됩니다.
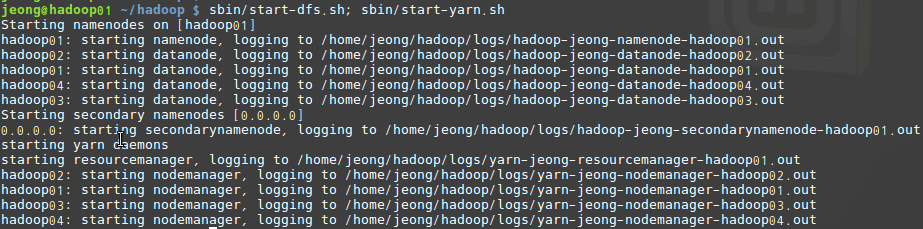
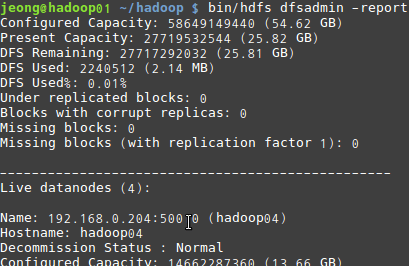
실행이 모두 완료되면 bin/hdfs dfsadmin -report 명령어와 bin/yarn node -list 명령어로 실행 상태를 확인할 수 있습니다. 본인이 생성한 Node 갯수에 맞게 출력되면 성공입니다.

VM 내 웹브라우저로도 구동 상태를 확인할 수 있습니다. 접속 주소는 http://hadoop01:50070 과 http://hadoop01:8088 입니다.
종료는 sbin/stop-dfs.sh; sbin/stop-yarn.sh 명령어로 합니다.
만약 제대로 동작하지 않으면, 설정 파일에 오류가 있을 확률이 큽니다. Hadoop을 종료한 후 오류를 수정하고, rm -rf /(hadoop 절대 경로)/work/data/*; rm -rf /(hadoop 절대 경로)/work/name/*; rm -rf /tmp/hadoop/* 를 모든 VM에서 실행한 후, NameNode VM에서는 추가로 bin/hdfs namenode -format 명령어를 실행해 초기화 해주세요.
후기
막상 다 끝내면 별거 아닌데, 은근히 시행착오가 많았습니다. 접속 에러의 원인을 한참 찾았었는데, 결국 hostname이 문제였었습니다. 그 외에는 큰 문제는 없었던 것 같네요.
얼마나 많은 분들이 VirtualBox로 Hadoop Cluster를 구동하실지 모르겠지만, 저처럼 학교 수업 때문에 하시는 분들은 좀 계실 수도 있겠네요. 실제로 구동할 때도 똑같은 방식으로 설정하지 않을까 싶습니다.
댓글